
VDL睿普通 PK GRE , 与VDL使用场景
睿普通是我们内部的一个产品代号,2014年因为公司需求而自研的一个产品。为什么会出现?下面给大家细细道来。
VDL 硬件产品的产生 & 基本介绍
作为一个传统的IDC企业,睿江云2007年成立,华南地区的IDC机房覆盖了珠三角,但是资源互通互访,网管网络构建,还是需要依赖运营商。
问题就来了:今日A提供商说要割接,中断1日;明天市政施工断一下。这样无疑对我们企业运营成本增加(扩容),网管响应反应都要求上来了(故障时候)。
当然我们开始也是使用GRE协议,用于网状网络的保证。但是在运营的故障中我们发现GRE的几个问题:
1. GRE 不能跑过大的流量 不到1G开始有问题。(PS:硬件厂家 交换机的GRE,具体我们不考究。
2. GRE 接口是不能应用 策略路由的。
3. GRE 是3层接口,对路由规划需要增加一层IP地址。
总之,传输有问题,就是头大、烦躁。
经过多年的问题积聚,我们还是开始自己的产品,建立一个2层的链路,通过互联网。把策略控制控制在核心交换机。只是负责链路建立&转发,把策略,路由的功能交付给核心的交换机。
VDL产生的效益
2016-05-27 23:37 年假休息,监控链路发现 A机房出局光缆中断了。(这次我比较轻松,得益于神器VDL。。)
我的机房架构:
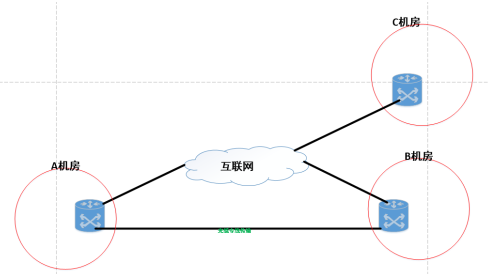
光缆中断导致的影响:
A. 跨机房的资源利用(IP、带宽都影响了)
B. 跨机房的数据链路备份(只能跑互联网,导致出口带宽跑高)
缺点:
A. 出口带宽利用率高
B. 通过出口互访A机房---B机房延时 58ms (不稳定,丢包)
这次我比较轻松了,以前的GRE太痛苦,太不灵活(GRE 是3层架构,配合PBR 用抓取源地址,指定下一跳)
以前的架构:

说明:
A. A机房、B机房、C机房 通过公网IP 做 GRE 隧道,然后建立OSPF,(修改COST比物理传输大)
B. 不能直接在GRE节点做应用PBR策略。(就算应用了,也不生效。要引入一个专门做策略的设备)
C. GRE 的MTU问题部分应用受影响。(这个无法优化)。
D. 我这里是CISCO+华为+H3C的设备
光缆断了的影响:
A. 客户丢包(必须的,因为GRE承载业务太差了,超过100Mb就有问题)
B. 客户不中断,我们只能处理到这里了。
优化后的方案:
使用VDL设备,跨机房的节点用(每个节点都要一台设备)。用来做2层VPN链路(跟L2TP有类似,跟传统的厂家,真不一样),下面我说一下现在架构:
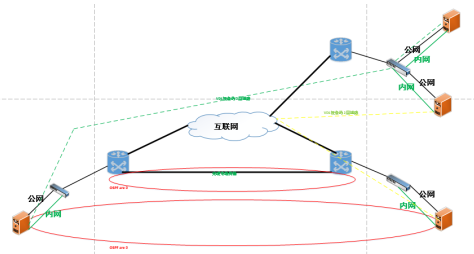
说明:
A. A 机房到 C机房 延时只有8ms (稳定、不丢包)
B. C 机房到 B机房 延时只有10ms (稳定、不丢包)
C. VDL设备(只是负责数据转发,×××链路建立 2个功能)。什么OSPF、VLAN都交给设备(cisco等)
所以目前架构:通过 C 机房 2套 VDL设备,把A ----C,C----B机房建立一条2层的×××链路,修改一下OSPF的COST值(主要跑物理的光缆传输)、配置一下track,对于跨机房的资源使用我们直接在设备上PBR就可以了。
专业的事情交个专业的设备(2层×××链路交给VDL设备;路由协议交给路由交换设备),这样我们的冗余保护能力得到了质量的提高。
本次割接客户反馈有一下闪断,但没有丢包。客户没有中断光缆的感觉:
1. 对客户的服务提高了SLA (服务提升)
2. 流量承载达到了6G。(当然要看看出口带宽空闲。我们20G的出口,利用率日常只有4G高锋)
本次光缆中断,没影响客户业务。(我只是给电话告诉商务2个事情:
A. 光缆中断了,要求抢修队伍。在这2日抢修好。
B. 出口带宽会上升,要跟运营商沟通这2日的带宽费用。
最后故障处理使用就1个电话的事情。。。。(等待光缆修复即可)。。。。。
2016-05-28 04点15分 光缆修复,流量跑回物理传输(过程其实完全不需要想以前想如何切流量,如何给业务一个接受的方案。
附图:神器

登陆页面
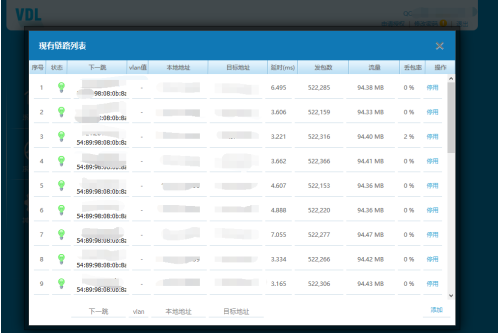
配置简单
睿江云官网链接:www.eflycloud.com

