
玩转KVM: 了解网卡软中断RPS
本篇给大家讲网卡中断如何提高虚拟机性能。
KVM的网卡软中断技术介绍
(1)硬中断
由与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。我们通常所说的中断指的是硬中断(hardirq)。
(2)软中断
为了满足实时系统的要求,中断处理应该是越快越好。linux为了实现这个特点,当中断发生的时候,硬中断处理那些短时间就可以完成的工作,而将那些处理事件比较长的工作,放到中断之后来完成,也就是软中断(softirq)来完成。
(3)聊聊RSS,RPS ,RFS
receive side steering,RSS利用网卡的多队列特性,将每个核分别跟网卡的一个首发队列绑定,以达到网卡硬中断和软中断均衡的负载在各个CPU上。他要求网卡必须要支持多队列特性。
RPS是receive package steering,类似rss机制,通过直接转发包到各个cpu进程上,在软件级实现中断,有助于防止单个网络接口卡的硬件队列成为网络流量的瓶颈。
receive flow steering,RFS需要依赖于RPS,他跟RPS不同的是不再简单的依据packet来做hash,而是根据flow的特性,即application在哪个核上来运行去做hash,从而使得有更好的数据局部性。
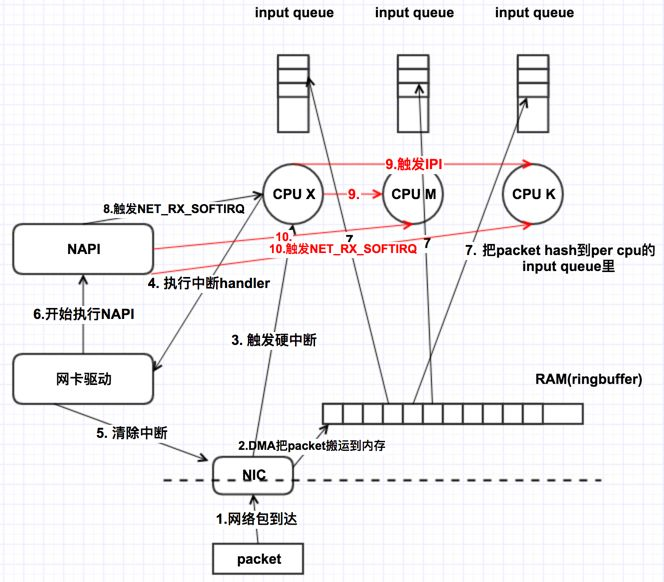
在这之前,软中断只能在硬中断所在CPU上处理,使用RPS后,网卡软中断就可以分发到其他的CPU上去做处理了。
但是,我们知道,任何一个优化特性都不是普遍适用的,都有他特定的场景来应用。
很多人对此可能会有疑惑,那很多优化功能不是都已经作为默认配置了么,如果不是普遍适用的,干嘛还要作为默认配置呢?
其实很简单,一个优化特性可以作为默认配置,依据我的理解,只需要满足下面这些特征即可:
1.对某些场景可以显著提升性能
2.对大部分场景无害
3.对某一部分场景可能会损伤性能
4.所以Linux的很多配置都是可以灵活配置供选择的
KVM的网卡软中断实战
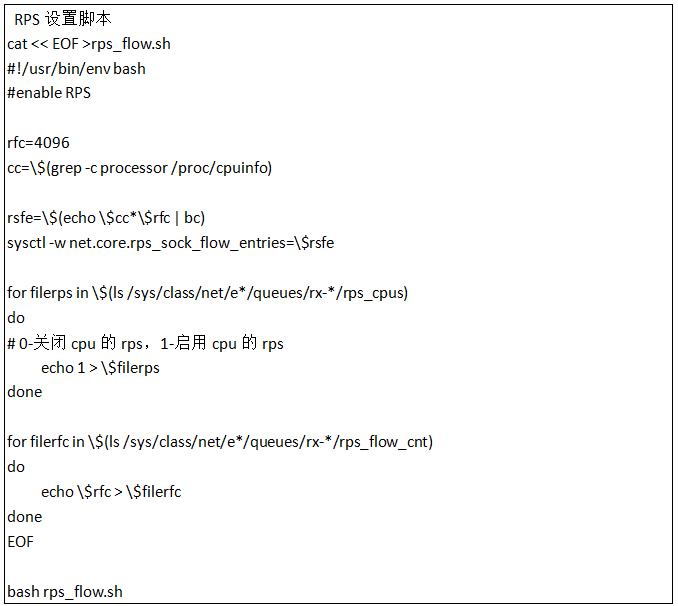
如果要设置RPS, RFS,则要满足以下条件:
1、虚拟机需要多线程
2、虚拟网卡需要支持多队列
系统默认是不开RPS
0(不开启rps功能)
/sys/class/net/eth0/queues/rx-0/rps_cpus00000000
/sys/class/net/eth0/queues/rx-1/rps_cpus00000000
/sys/class/net/eth0/queues/rx-2/rps_cpus00000000
/sys/class/net/eth0/queues/rx-3/rps_cpus00000000
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt0
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 0
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 0
/proc/sys/net/core/rps_sock_flow_entries0
one cpu per queue(每队列绑定到1个CPU核上)
/sys/class/net/eth0/queues/rx-0/rps_cpus00000001
/sys/class/net/eth0/queues/rx-1/rps_cpus00000002
/sys/class/net/eth0/queues/rx-2/rps_cpus00000004
/sys/class/net/eth0/queues/rx-3/rps_cpus00000008
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt 4096
/proc/sys/net/core/rps_sock_flow_entries32768
all cpus per queue(每队列绑定到所有cpu核上)
/sys/class/net/eth0/queues/rx-0/rps_cpus000000ff
/sys/class/net/eth0/queues/rx-1/rps_cpus000000ff
/sys/class/net/eth0/queues/rx-2/rps_cpus000000ff
/sys/class/net/eth0/queues/rx-3/rps_cpus000000ff
/sys/class/net/eth0/queues/rx-0/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-1/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-2/rps_flow_cnt 4096
/sys/class/net/eth0/queues/rx-3/rps_flow_cnt4096
/proc/sys/net/core/rps_sock_flow_entries32768
总结
在极端情况下RPS可以获得非常好的性能,可惜实际情况下反而对整机整体负载有所妨害,主要是进程调度导致的(1)cpu缓存丢失导致,所以在应用负载已经非常高的情况下开启RPS是没意义的做法(开启RFS会稍微好转但是作用也不大)。
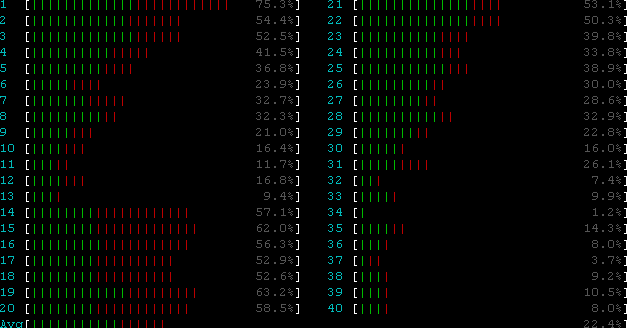
下图所示为不开启RPS的情况。可见左侧cpu存在较高的%sys负载,是因为网卡队列都绑定在左侧的几个cpu上。
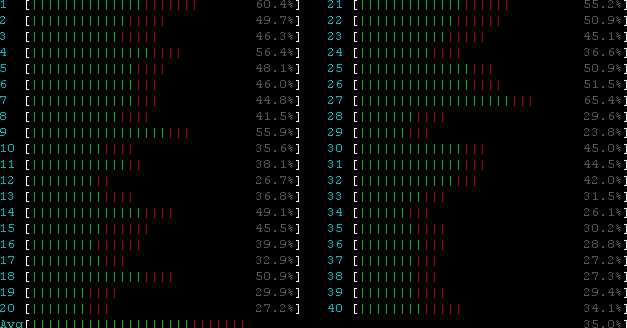
下图所示为同时开启RPS的情况。可见%sys较为均衡,同时(2)整机负载略有上升。这是因为:收到网卡中断的CPU会向其他CPU发IPI中断,这体现在CPU的%irq上需要处理packet的cpu会收到NET_RX_SOFTIRQ软中断,这体现再CPU的%soft上。请注意,RPS并不会减少第一个CPU的软中断次数,但是会额外给其他的CPU增加软中断。他减少的是第一个CPU的软中断的执行时间,即软中断里不再需要那么多的时间去走协议栈做包解析,把这个时间给均摊到其他的CPU上去了。
所以优化还是要按实际情况来考虑的哦。
附录:
睿江云官网链接:https://www.eflycloud.com/home?from=RJ0032

